Posts
Transforming a legacy poll API into a Push Service
Posted on June 26, 2025 • 8 min read • 1,549 words

By Alex Richardson (Director of Engineering)
Background
At Arctic Shores we have to develop lots of integrations to our partners and other third parties, the majority of these are Applicant Tracking Systems (ATSs) and are a way for our customers to bulk add candidates to UNA without having to manually add each one or perform a CSV upload. While we provide an API that our customer or their ATS provider can integrate against, we also sometimes initiate the integration to the ATS.
In the majority of cases, the ATS will push a candidate to us once they are in the required status the customer needs (usually something as simple as ‘Assessment’). This allows UNA to create and invite the candidate on demand, and then finally send the results to the ATS once the candidate has completed their assessment.
We like this for many reasons:
- It’s event driven, and therefore fits well with UNAs architecture
- It isn’t unnecessarily computationally expensive - we don’t need to have a continual polling processes checking for new data
- Everything happens in almost real time (its almost due to UNAs event driven architecture, there will be always some seconds of lag)
- It’s easy for UNA to directly send errors back to the ATS should it need to
However, on a recent (and major) integration, they had no ability to push data to us. There was no scope for custom improvements to the ATS, our only way to get the necessary candidate data to add to UNA was a single ‘read’ API that returned all applicable candidates as a json list.
This immediately throws up the following problems:
- This API isn’t a stateful message queue, once we have read and processed a candidate it will still exist on the API response when we poll again
- The response wasn’t paginated, therefore on super high volumes of candidates we could run the risk of failed requests due to breaking various limits on our load balancers, nginx, WAFs etc
- How do we send back errors?
- How do we balance a quick response without consuming too many resources continually polling?
But with some AWS tooling, we were able to add a deduplication layer to our polling process, and transform the polling interface so that to UNA it was in effect a push interface. We essentially managed to get an at-least-once delivery from this raw API, and protect our services from this legacy domain leaking logic into them. In this blog I’ll describe how we got there.
Our Initial Approach
From the start we knew we needed two things:
- Some form of state to track which candidates we had processed and which we hadn’t
- To not do this directly on our postgres database, otherwise one customers high candidate volume could affect other customers
We were quickly able to find one useful feature of the API we were calling, we were able to pass in a time range to the call so that only candidates moved into the correct status in that time window were returned. This reduced the risk of sudden high volumes of candidates (though obviously didn’t remove it entirely). Due to this enhancement, it led us to look at a more frequent polling schedule, ensuring the volume returned at any one time is low, the database read on the ATS side is reduced, and UNA can process in a near real-time manner.
A naive solution to all this would be to just poll every 5 minutes for the last 5 minutes of candidates. However, this would only get you to at-most-once delivery, not at-least-once, since you cannot be completely sure each poll happens exactly 5 minutes apart—and with no candidates slipping through the gaps. This led us to realise that overlaps, and reading the same candidate twice needs to be baked into the process, and be handled.
We decided on the following two part solution:
- A DynamoDB table to store the state of which candidates we had seen, with the UNA Assessment ID and the candidate email address as a Hash/Range key pair (In UNA only one candidate is allowed per assessment, so we restrict on the email provided)
- A Kinesis event stream attached to the DynamoDB table to capture all events on the table (DynamoDB as the ability to automatically emit all events that happen on the table to a Kinesis even stream)
This would give us the following flow:
- A process on a scheduled timer (likely a lambda) calls the ATS API every 5 minutes (but configurable), and receives all candidates moved into the correct phase within the last 10 minutes (so we have definate overlap)
- These are all written to a DynamoDB table using key constraints to not allow writes if the key already exists, errors here are then handled and discarded (So only NEW candidates can be written)
- The events emitted to the kinesis stream are therefore only for new candidates, and can then be consumed by UNA to create and invite candidates
Concerns and Pivots
This gave us a deduplication layer that contained all this logic in one place, UNA was able to stay unaware at how candidates were being obtained.
There was a weakness still in how we were making that polling call to the ATS API, and saw the following:
- Due to there being no pagination on the API call we were still at risk if the candidate volume is too high, the call could timeout and we could miss candidates
- With large candidate volumes, the poller process would have to write a lot of entries to the DynamoDB table, the process is not atomic so should it fail part way through processing we could miss candidates
On the first issue we knew we needed good error handling and retry logic around the poller process, so we opted to use a lambda to trigger this. This allowed us to lean on lambdas built in error handling, retry and dead letter functionality to divide and conquer the problem should we hit very high candidate volume suddenly on a poll. This didn’t completely remove the issue, but it did handle it in all but the most pathological cases.
For the second issue we looked at the batch write functionality in DynamoDB, this seemed built for large data ingestion and seemed to suit our use case. However, batch writes don’t support key conditions on write, and this was how we were planning on blocking duplicate candidates from being written to the DB. This meant that in having an optimal way of writing the data to the table, we then lost our way of ensuring only the first instance of a candidate email/campaign ID is written to the table and therefore processed by UNA.
Our solution was to still use the batch writing process, but instead move the deduplication logic to the consumer of the kinesis events. When you connect a kinesis stream to DynamoDB events you get metadata about what the operation is, so you get events of type INSERT and you get events of type MODIFY. We could then have the lambda ignore MODIFY events and only process INSERT events (the first time that candidate has been seen). Moving this deduplication step to the lambda code also allowed us to create stronger alerting around duplication of candidates (if a candidate had been sent down different external recruitment campaigns that mapped to the same UNA Assessment).
Final Architecture and Conclusions
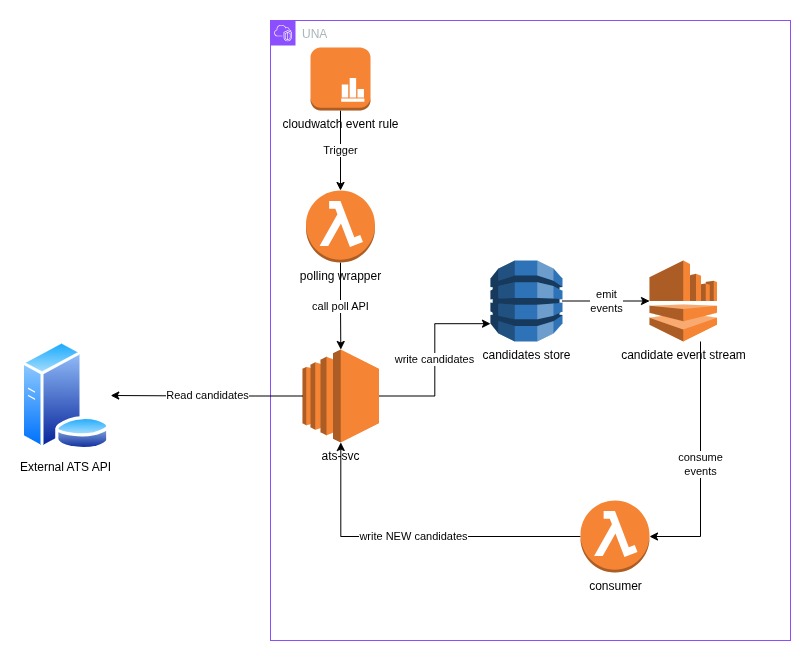
Our final flow became:
- A lambda on a configurable polling schedule calls an api on our internal ats-svc, passing in account information and a time interval - this is triggered at a custom rate via a cloudwatch event rule
- The service then calls the external API to fetch candidates moved to the correct status in the past time interval. It then batch stores all these candidates into the DynamoDB table.
- Events are emitted from the table, a different lambda consumes these events, and when the event is of type INSERT it then calls a creation API on our ats-svc.
- If the lambda detects duplicates it can send the necessary alerts
The advantage of this approach is the complexity around deduplication is kept outside of UNA and the product in general, it’s a pre-processing filter to transform a basic API read into a near real time push architecture.
Once we had the idea it was quite trivial to implement, it’s just a few AWS resources connected together along with some simple logic in the lambdas to process the events. We also have confidence all candidates will be captured correctly, we can set up strong error handling and alerting based on any issues and can handle high volumes of candidates without draining resources on our ats-svc or it’s database until we are sure we have a new candidate to store. Our final steps will be the error handling in the pathological cases (100k candidates get moved into the assessment status at the exact same point in time!). Currently, we have some strong alerting so if something like this happens we can react to it, however we don’t want this baked into our process. So the final thing to look at will be how to best divide and conquer any errors on polling so that we retry in a tighter and tighter time frame.